Limiting density of discrete points
In information theory, the limiting density of discrete points is an adjustment to the formula of Claude Elwood Shannon for differential entropy.
It was formulated by Edwin Thompson Jaynes to address defects in the initial definition of differential entropy.
Definition
Shannon originally wrote down the following formula for the entropy of a continuous distribution, known as differential entropy:
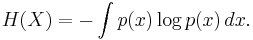
Unlike Shannon's formula for the discrete entropy, however, this is not the result of any derivation (Shannon simply replaced the summation symbol in the discrete version with an integral) and it turns out to lack many of the properties that make the discrete entropy a useful measure of uncertainty. In particular, it is not invariant under a change of variables and can even become negative.
Jaynes (1963, 1968) argued that the formula for the continuous entropy should be derived by taking the limit of increasingly dense discrete distributions. Suppose that we have a set of  discrete points
discrete points 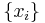 , such that in the limit
, such that in the limit 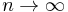 their density approaches a function
their density approaches a function 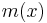 called the invariant measure.
called the invariant measure.
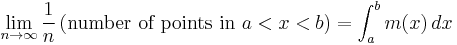
Jaynes derived from this the following formula for the continuous entropy, which he argued should be taken as the correct formula:
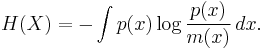
It is formally similar to but conceptually distinct from the (negative of the) Kullback–Leibler divergence or relative entropy, which is comparison measure between two probability distributions. The formula for the Kullback-Leibler divergence is similar, except that the invariant measure is replaced by a second probability density function 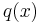 . In Jaynes' formula, is not a probability density but simply a density. In particular it does not have to be normalised so as to sum to 1.
. In Jaynes' formula, is not a probability density but simply a density. In particular it does not have to be normalised so as to sum to 1.
Jaynes' continuous entropy formula and the relative entropy share the property of being invariant under a change of variables, which solves many of the difficulties that come from applying Shannon's continuous entropy formula.
It is the inclusion of the invariant measure 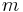 that ensures the formula's invariance under a change of variables, since both and
that ensures the formula's invariance under a change of variables, since both and 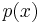 must be transformed in the same way.
must be transformed in the same way.
References
- Jaynes, E. T., 1963, "Information Theory and Statistical Mechanics", in Statistical Physics, K. Ford (ed.), Benjamin, New York, p. 181.
- Jaynes, E. T., 1968, "Prior Probabilities", IEEE Trans. on Systems Science and Cybernetics, SSC-4, 227.
- Jaynes, E. T., 2003, Probability Theory: The Logic of Science, Cambridge University Press.